Stack Overflow having some kind of maintenance is scary. In this post, I'm solving this once and for all by hosting a local copy of the answers.
When writing software, there is always something that's the dev worst nightmare, be it a mix-match of tab and space in python, a missing semicolon in c, you get the point.
But the most scary thing is when you can't steal code search for help
So how do I download Stack Overflow locally on my NAS? The noobie approach would be to just scrape every question and re-host the site statically, the issue is that Stack Overflow is well... quite big and while I probably would have the space it's really stupid especially considering the second option
ZIM files
ZIM stands for "Zeno IMproved", as it replaces the earlier Zeno file format. Its file compression uses LZMA2.
The ZIM file format is an open file format that stores wiki content for offline usage. Its primary focus is the contents of Wikipedia and other Wikimedia projects.
The format allows for the compression of articles, features a full-text search index and native category and image handling similar to MediaWiki, and the entire file is easily indexable and readable using a program like Kiwix – unlike native Wikipedia XML database dumps.
Well that sounds perfect, where can I get the Stack Overflow one. Well, the kiwix wiki provides a list of content : https://wiki.kiwix.org/wiki/Content_in_all_languages.
Among them is Stack Overflow in multiple languages (es, ja, pt, ru) including the main one which is a mind-bending 134 GB of compressed data, that's more than the entire dump of English Wikipedia (2021-12) which is around 86 GB 😲.
There is another issue tho, the dump provided by kiwix dates from February 2019 which isn't that old, but, in a field such a software/firmware development which is constantly moving and innovating I feel that having a 3 years old dump might lack some newer stuff.
So how do we get a newer ZIM file, well searching around it turns out that the Stack Exchange post database dumps quarterly on the internet archive:
Looking at the stackoverflow.com-PostHistory.7z we can see that the dump was done December of 2021, much better, the dump is also 162 GB 🤯
The thing is, I'm not in the mood of writing a script to process 162 GB of data (I will probably write it a some point because it'll probably be a great exercise about managing huge datasets).
So to solve this I browsed a bit more and of course reddit came to the rescue: https://www.reddit.com/r/DataHoarder/comments/pm8xoy/updated_stack_overflow_zim_file_20210906/
Someone generated a zim file for September 2021 (which still works for me). This dump has 21,958,765 articles and weight 161GB, not bad!
Well next was downloading the dump, at least they provided a torrent, and with 3/4 peers at max it took around 2 days to download which is a lot less fun. But the important thing is that the file is sitting on my nas, Yay
Ok now that I have the file I need a way to read it, the standart for reading ZIM fil is the Kiwix reader, but there are others (like web-archives and multiple command line ones).
Kiwix it is, so I created a new container on my proxmox cluster and started things off by mount my NAS. This required me to enable the CIFS feature on my container, while I was there as I'll be using docker to launch Kiwix, I also enabled the support for nesting.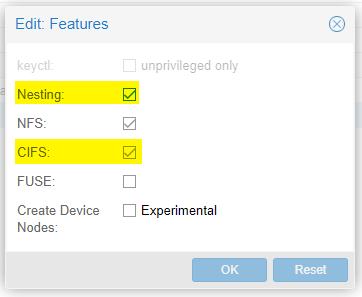



version: '3'
services:
kiwix:
image: kiwix/kiwix-serve
restart: unless-stopped
command: 'stackoverflow.com_en_all.zim'
ports:
- '9999:80'
volumes:
- "/nas/common/applications/wikipedia/dumps:/data"
First, we want to use the kiwix/kiwix-serve image, and set it to restart unless we stop it manually.
The image then expects the file name as the start command, so I set it to the downloaded ZIM file (Note, multiple files can be used here by separating them with a whitespace or simply using *.zim).
I then forwarded the port 80 inside the container to port 9999 of the host and maped the nas folder to the /data folder inside de container.
After executing "docker-compose up -d" and waiting a bit for it to start (remember it still is a 162 GB file) I was greeted by a nice welcome page on my browser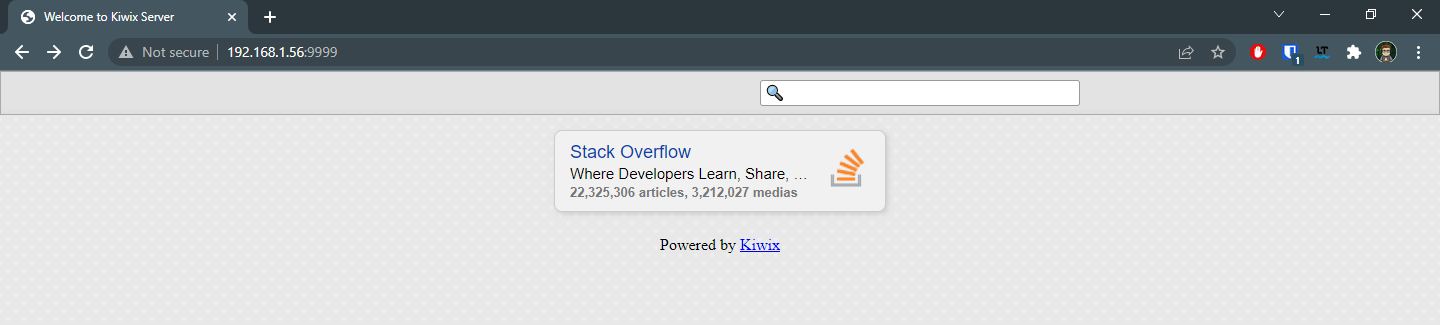
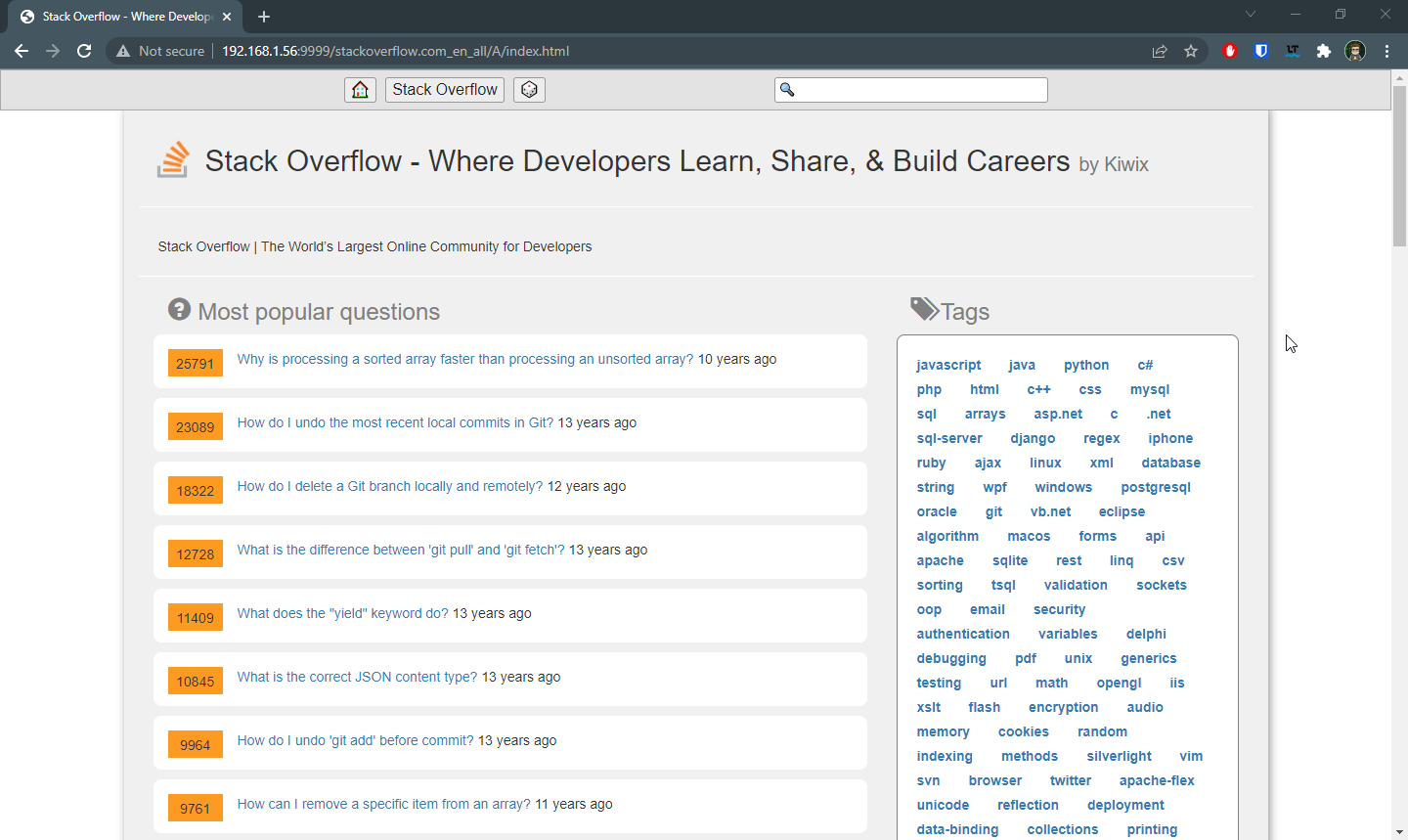
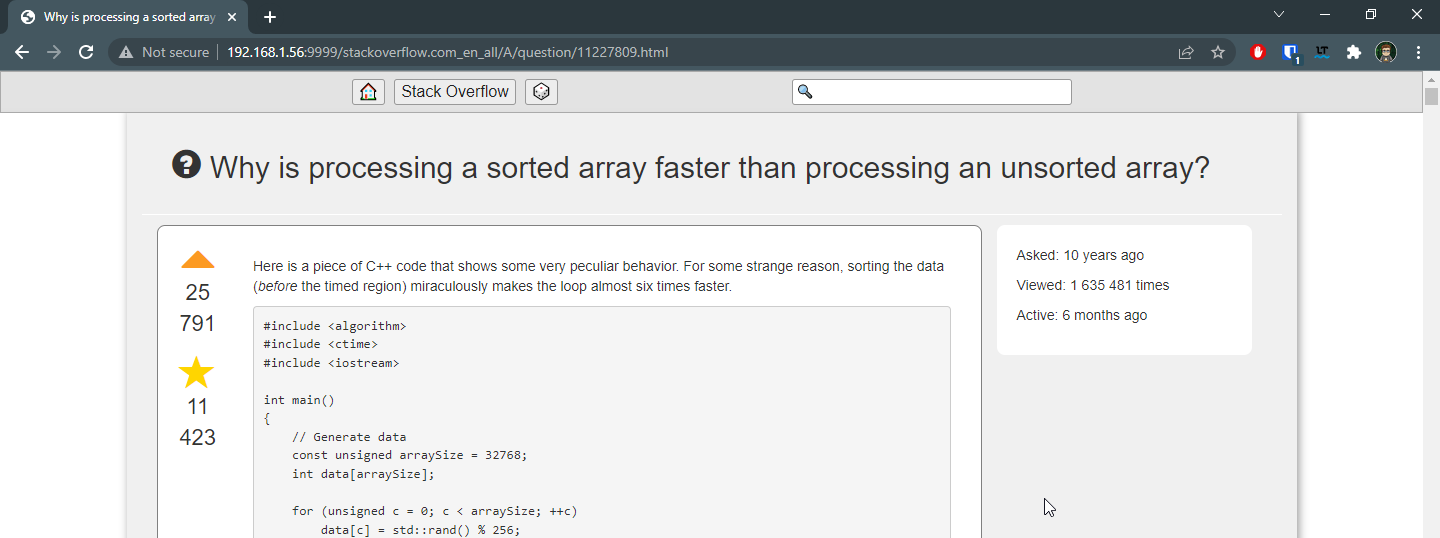
Lets take this question:
The url https://stackoverflow.com/questions/477816/what-is-the-correct-json-content-type can be decomposed into multiple parts:
It turns out that I can simply use the question ID and append it to the end of the kiwix server, like this: http://192.168.1.56:9999/stackoverflow.com_en_all/A/question/477816.html
And of course it loads fine: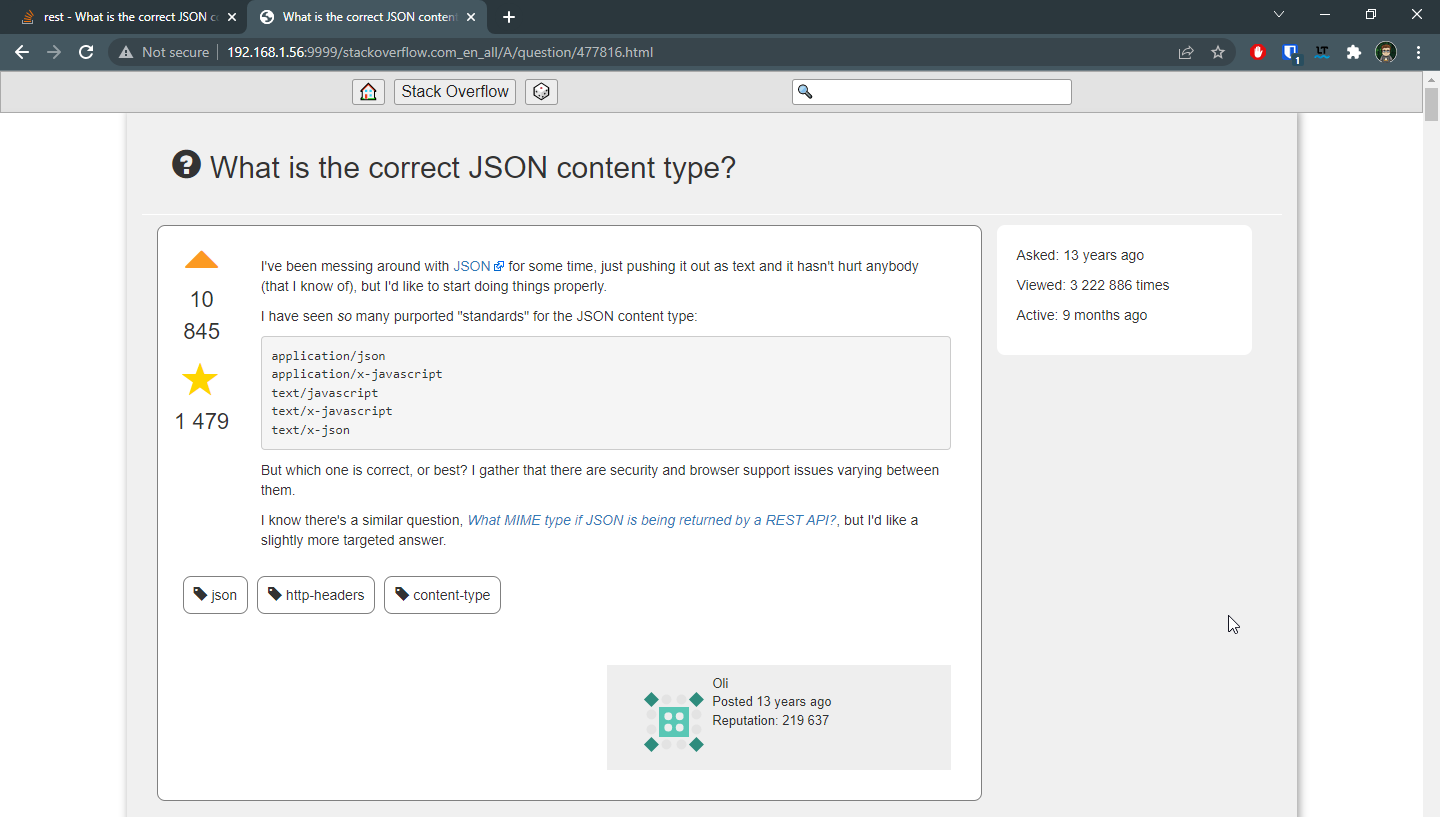
So, lets write a bit of JS that detects when stackoverflow is in maintenance (or simply crashed) and redirect to my selfhosted Kiwix instance.
First I created a manifest.json file describing the extension. It also specifies that the script "content.js" will be executed when any page that matches the url to this glob: "https://stackoverflow.com/questions//"
{
"name": "StackOverflow to Kiwix redirector",
"description": "Redirects to a self-hosted kiwix instance if StackOverflow is down",
"version": "1.0",
"manifest_version": 3,
"icons": {
"16": "/images/kiwix.png",
"32": "/images/kiwix.png",
"48": "/images/kiwix.png",
"128": "/images/kiwix.png"
},
"content_scripts": [
{
"matches": [
"https://stackoverflow.com/questions/*/*"
],
"js": ["content.js"]
}
]
}
The script itself is pretty simple, it simply checks for the presence of the "a" element which contains the question title. And if it doesn't find it or errors out, redirect to the local kiwix server
const LOCAL_URI="http://wiki.lan/stackoverflow.com_en_all/A/question/{{ID}}.html"
function redirect() {
alert("StackOverflow is broken, redirecting to local instance")
var id = window.location.href.split("/").reverse()[1]
window.location = LOCAL_URI.replace("{{ID}}", id)
}
window.addEventListener('load', function () {
try {
var title = document.querySelector("#question-header > h1 > a")
if (title == null){
redirect()
}
} catch (error) {
redirect()
}
})
A simple way to test if the extension is working is to open the developer mode and go into the mobile view. As the CSS of Stack Overflow is different on pc than on mobile, the query selector for the title is also different, meaning that the extension will consistently redirect to the kiwix server. See for yourself:
Well, I just solved the biggest issue of software development, before you go hate me, this post was more to present kiwix and the ZIM file format than making sure that I always have access to Stack Overflow (it is pretty cool tho).
Want to chat about this article? Just post a message down here. Chat is powered by giscus and all discussions can be found here: TheStaticTurtle/blog-comments
